
Database Sharding
Let’s imagine an app is well-known and receives a lot of traffic from all around the world. As a result, your database will be bombarded with thousands of new records every day. Now the subject of how to manage user data and for users emerges. In this case, database sharding is the appropriate course of action.
What is Database Sharding?
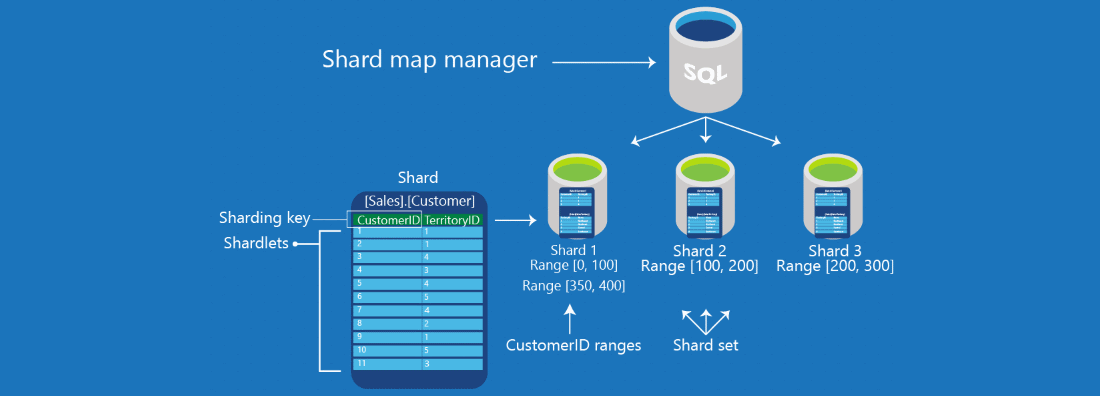
Data partitioning is known as sharding. Sharding is a technique for splitting a large dataset into many databases using a specific partitioning algorithm. In general, there are two types of sharding: vertical and horizontal.
Vertical sharding is a data storage strategy that divides data into several sets based on diving qualities. Let’s imagine we have a single table/dataset containing user data with roughly 25 different characteristics. These attributes can be divided into different tables/sets, such as distinct tables/sets for personal information, login credentials, health information, biographic information, and so on.
Horizontal sharding distributes data into various tables or locations based on rows. i.e., we have data from 4 million people. We used sharding to divide data into four separate groups of one million people based on, say, geographies.
Strategy
Partition or shard A key is a subset of the primary key that aids in the distribution of data. Plan how you’ll handle read-write operations on the data.
The sharding procedure is handled differently by each database type, however it may be separated into two types in common cases. A logical shard is a storage strategy that uses the same partition keys for various data sets. Something with many logical shards is referred to as a physical shard.
Algorithmic Sharding
It takes data as input, applies a hash function to it to get a hash output, and then stores that record to the appropriate shard based on the hash. As far as I’m aware, the modulus operator is most commonly used to take a subset of data as input and construct a number of shards.
Because we’ll be carrying the partition key with us. The reads will be done on a single database. In the absence of a partition key, each database must be searched to obtain the records. In general, this type of sharding is appropriate for key-value databases since the sharding function distributes data uniformly according to the logic stated in the function.
Dynamic Sharding
There will be a finder service in dynamic sharding that interacts with each read-write entry to locate the correct database. The locator service will efficiently handle read and write queries based on the various partition keys provided. As with algorithmic sharding, the partition key will be available to all queries. Without it, queries must scan all databases for records.
It is not as uniform as an algorithmic one, and it presents a number of implementation issues. The locator service is the point at which all queries are sent, therefore if it fails, the entire structure would collapse. It’s difficult to find those records in the database in the event of routing problems, and it’s a time-consuming operation.
Another notion that has gained popularity in this area is entity groups, which refers to storing all types of data for a single user with the same partition key. This will allow us to read things quickly and effectively, although cross partitioned queries may occur, but their frequency will be smaller, resulting in better outcomes.
Advantages
High Availability & Optimized Results
Each query will specify partitioned databases with a partition key. The query is limited to a single database. As a result, a speedy and optimum response is achieved.
Easy Failure Recovery
Distributed architecture is at the heart of Data Sharding. Only specific partitioned data will be impacted if one of the partitions fails; the remainder will continue to function normally. Only replica or database backups of that partition will address the problem.
Points to Consider
Selection Of Strategy
A suitable technique for dealing with the sharding process should be chosen. Changing strategy in the middle of a project will be too difficult.
Complicated Architecture
Implementing sharding is not about solving a complex problem with a simple solution. The connection between database and application architecture will become more sophisticated as time goes on.
Difficulty In Back To Non-sharding Architecture
Database sharding has a high level of complexity. It will be difficult to return to a non-sharding design after implementation.
Conclusion
When dealing with enormous amounts of data, database sharding comes in handy. Concrete efforts in developing and implementing a sharding strategy are required. Data sharding makes data management much more difficult. I propose using database sharding only when absolutely necessary, and opting for horizontal sharding instead.









Comment (1)
After study several of the web sites on the site now, we truly much like your technique of blogging. I bookmarked it to my bookmark website list and will be checking back soon.